Model architectures#
Introduction#
You can see a list of supported architectures/variants by using:
from deeplabcut.pose_estimation_pytorch import available_models
print(available_models())
You can see a list of supported object detection architectures/variants by using:
from deeplabcut.pose_estimation_pytorch import available_detectors
print(available_detectors())
Neural Networks Architectures#
Several architectures are currently implemented in DeepLabCut PyTorch (more will come, and you can add more easily in our new model registry). Also check out the explanations of bottom-up/top-down below.
ResNets#
Adapted from He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2016. and [Insafutdinov, Eldar et al. “DeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model”. European Conference on Computer Vision (ECCV) 2016.]
Current bottom-up variants are
resnet_50,resnet_101Current top-down variants are
top_down_resnet_101,top_down_resnet_50
HRNet#
Current variants are
hrnet_w18,hrnet_w32,hrnet_w48,Current top-down variants are
top_down_hrnet_w18,top_down_hrnet_w32,top_down_hrnet_w48Slower but typically more powerful than ResNets
DEKR#
This model is a bottom-up model using HRNet as a backbone. It learns to predict the center of each animal, and predicts the offset between each animal center and their keypoints
Current variants that are implemented (from smallest to largest):
dekr_w18,dekr_w32,dekr_w48Note, this is a powerful multi-animal model but very heavy (slow)
BUCTD#

This is a top-performing multi-animal method that combines the strengths of bottom-up and top-down approaches, and delivers exceptional performance on humans too (which are also animals)
It can be used with a diverse set of architectures. Current variants are:
ctd_coam_w32,ctd_coam_w48/ctd_coam_w48_human,ctd_prenet_hrnet_w32,ctd_prenet_hrnet_w48,ctd_prenet_rtmpose_s,ctd_prenet_rtmpose_m,ctd_prenet_rtmpose_x/ctd_prenet_rtmpose_x_human
DLCRNet#
This model uses a multi-scale variant of a ResNet as a backbone, and part-affinity fields to assemble individuals
Variants:
dlcrnet_stride16_ms5,dlcrnet_stride32_ms5
CSPNeXt#
From Jiang, Tao et al. “RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose” and “CSPNeXt: A new efficient token hybrid backbone”
CSPNeXt is a convolutional backbone designed for efficient computer vision models.
It can be selected directly as a backbone
It is also used as the backbone of other model architectures, including RTMPose.
When CSPNeXt is selected directly, it will be combined with the standard head appropriate for the project type.
Available CSPNeXt variants include
cspnext_s,cspnext_m, andcspnext_x.
RTMPose#
From Jiang, Tao et al. “RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose”
Top-down pose estimation model using a fast CSPNeXt backbone with a SimCC-style head
Variants:
rtmpose_s,rtmpose_m,rtmpose_x
AnimalTokenPose#
Adapted from Li, Yanjie, et al. “Tokenpose: Learning keypoint tokens for human pose estimation.” Proceedings of the IEEE/CVF International conference on computer vision. 2021. as in Ye et al. “SuperAnimal pretrained pose estimation models for behavioral analysis.” Nature Communications. 2024
One variant is implemented as:
animal_tokenpose_basefor video inference only (we don’t support directly training this within deeplabcut)
Information on Single Animal Models#
Single-animal models are composed of a backbone (encoder) and a head (decoder)
predicting the position of keypoints. The default head contains a single deconvolutional
layer. To create the single animal model composed of a backbone and head, you can call
deeplabcut.create_training_dataset with net_type set to the backbone name (e.g.
resnet_50 or hrnet_w32).
If you want to add a second deconvolutional layer (which will make your model slower,
but it might improve performance), you can simply edit your pytorch_config.yaml file.
Of course, any multi-animal model can also be used for single-animal projects!
Approaches to Multi-Animal pose estimation#
Single-animal pose estimation is quite straightforward: the model takes an image as input, and it outputs the predicted coordinate of each bodypart.
Multi-animal pose estimation is more complex. Not only do you need to localize bodyparts in the image, but you also need to group bodyparts per individual. There are two main approaches to multi-animal pose estimation.
Bottom-up estimation#
The first approach, bottom-up pose estimation, starts by detecting bodyparts in the image before figuring out how they belong together (i.e., which keypoints belong to the same animal).
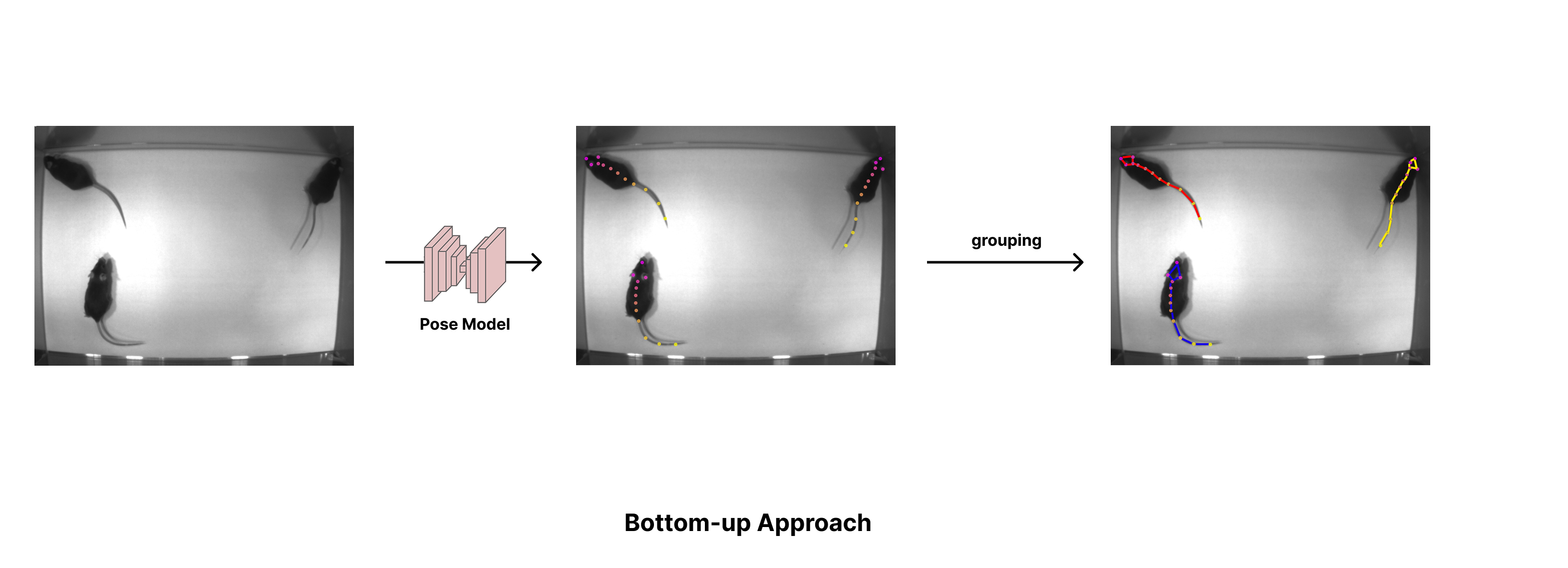
Backbones with Part-Affinity Fields#
As in DeepLabCut 2.X, the base multi-animal model is composed of a backbone (encoder) and a head predicting keypoints and part-affinity fields (PAFs). These PAFs are used to assemble keypoints for individuals.
Passing a backbone as a net type (e.g., resnet_50, hrnet_w32) for a multi-animal
project will create a model consisting of a backbone and a heatmap + PAF head.
Top-down estimation#
The second approach, top-down pose estimation, uses a two-step approach. A first model (an object detector) is used to localize every animal present in the image through its bounding box. Then, the pose for each animal is determined by predicting bodyparts in each bounding box. The pose estimation
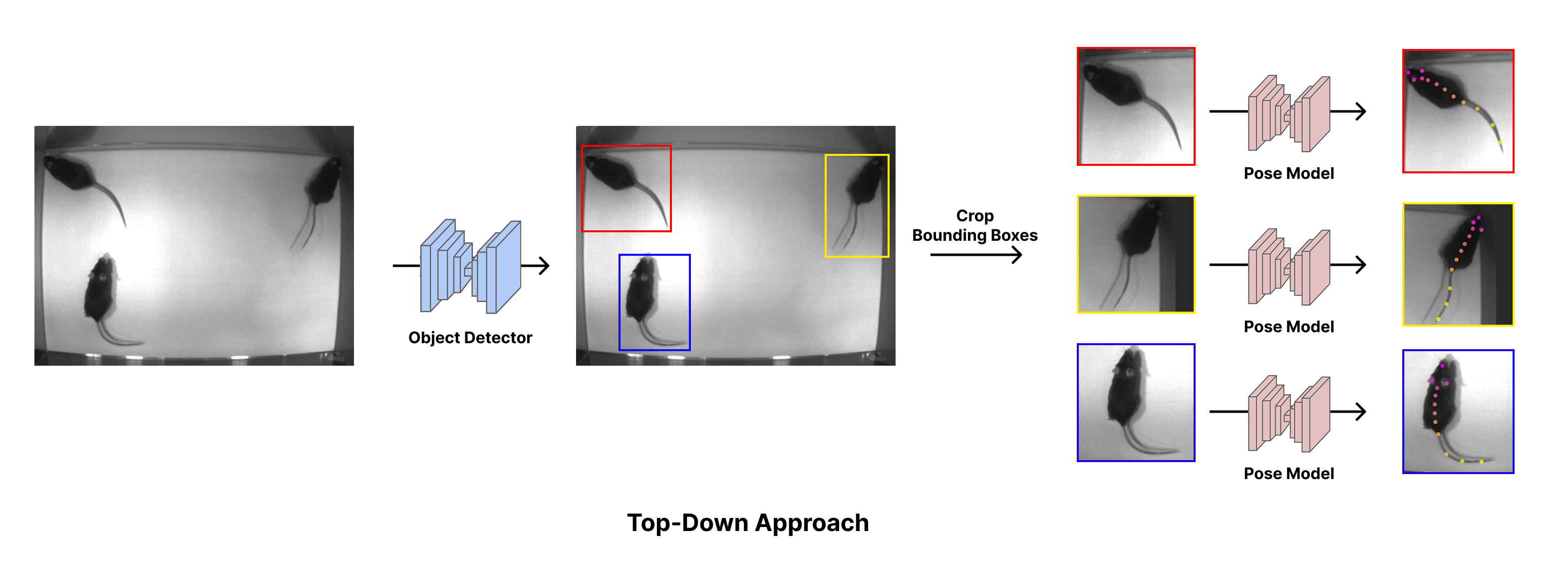
The top-down approach tends to be more accurate in less crowded scenes, as the pose model only needs to process the pixels related to a single animal. However, in more crowded scenes, the pose estimation task becomes ambiguous. Multiple overlapping individuals will have very similar bounding boxes, and the pose model has no way of knowing which animal it is supposed to predict keypoints for.
The bottom-up approach does not have this ambiguïty, and also has the advantage of only needing to run a pose estimation model, instead of needing to run an object detector first. However, grouping keypoints is a difficult problem.
Hence any single-animal model can be transformed into a top-down, multi-animal model. To
do so, simply prefix top_down to your single-animal model name. Currently, the
following detectors are available: ssdlite, fasterrcnn_mobilenet_v3_large_fpn,
fasterrcnn_resnet50_fpn_v2.
Hybrid, Bottom-up (BU) plus a ``conditioned” Top-down (CTD)#
A new approach to pose estimation, named bottom-up conditioned top-down (or BUCTD), was introduced in Zhou, Stoffl, Mathis, Mathis. “Rethinking Pose Estimation in Crowds: Overcoming the Detection Information Bottleneck and Ambiguity.” Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 2023 . It’s a hybrid two-stage approach leveraging the strengths of the bottom-up and top-down approaches to overcome the ambiguïty introduced through bounding boxes. Instead of using an object detection model to localize individuals, it uses a bottom-up pose estimation model. The predictions made by the bottom-up model are given as proposals (or conditions) to the pose estimation model. This is illustrated in the figure below. In modern language, one could state that CTD models are “pose-promptable”.
 Zhou, Mu, et al. “Rethinking pose estimation in crowds: overcoming the
detection information bottleneck and ambiguity.” Proceedings of the IEEE/CVF
International Conference on Computer Vision. 2023.
Zhou, Mu, et al. “Rethinking pose estimation in crowds: overcoming the
detection information bottleneck and ambiguity.” Proceedings of the IEEE/CVF
International Conference on Computer Vision. 2023.